Содержание
Коротко
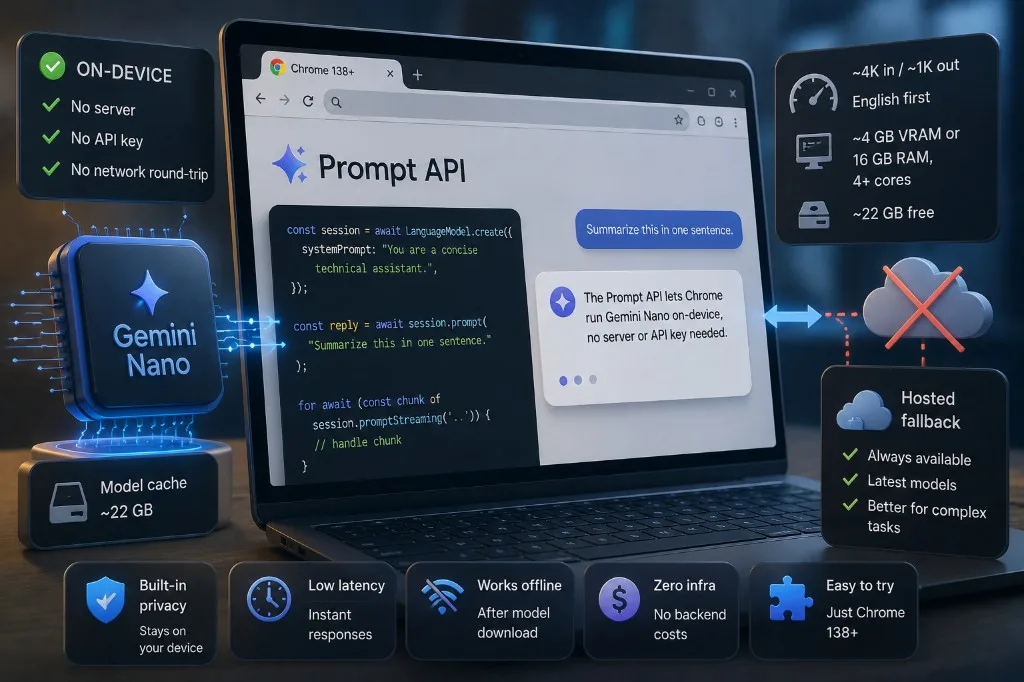
В Chrome 138+ появился Prompt API: вызов await LanguageModel.create() запускает Gemini Nano на устройстве — без сервера, ключа и сетевого round-trip. Модель (~4 GB) подтягивается с обновлениями браузера. Для продакшена всё равно нужен fallback на hosted API: подходит далеко не каждый пользователь.
Что произошло
Спека и флаги (optimization-guide-on-device-model, prompt-api-for-gemini-nano) эволюционировали с 2024 года; к маю 2026 API доступен в Stable и через Origin Trial для продакшен-доменов. На HN и в расширениях (Decaf, перевод субтитров YouTube) уже шипят фичи «за выходные».
Минимальный сценарий:
const session = await LanguageModel.create({
systemPrompt: "You are a concise technical assistant.",
});
const reply = await session.prompt("Summarize this in one sentence.");
Стриминг — session.promptStreaming() с for await, отмена — через AbortSignal.
Почему это важно
Это третий вектор «дешёвого AI» рядом с локальными серверами (Ollama) и open weights: пользователю ничего не ставить — достаточно Chrome. Для задач «автодополнение уровня» (теги, тон текста, короткое резюме) маржа hosted API сжимается.
Ограничения честные:
| Параметр | Реальность |
|---|---|
| Контекст | ~4K in / ~1K out |
| Качество языков | English в приоритете |
| Железо | ~4 GB VRAM или 16 GB RAM + 4+ ядра |
| Диск | ~22 GB свободно под кэш модели |
| Задачи | Плохо: длинный RAG, код, цепочки рассуждений |
Mozilla предупреждает о vendor lock-in промптов под Nano — fallback нужен и как страховка на Safari/Firefox, и как защита от смены поведения модели при автообновлении Chrome.
На практике
- Проверять
LanguageModel.availability()— статусыdownloadable/downloading/available. - Объединить on-device и hosted в один
AsyncIterable<string>— UI не знает, откуда токены. - На fallback вести дешёвую модель (Flash/Haiku), а не flagship — иначе экономия только переносится.
- Не обещать «данные не уходят с устройства» без прозрачности — индикаторов «сайт использует on-device AI» в UI браузера пока нет.
- JSON mode нестабилен — парсить с retry; длинные страницы резать (map-reduce), иначе 4K кончается быстро.
Правило выбора: <500 токенов ввод, <200 вывод, ошибка некритична → Nano; иначе hosted.
Итог
Prompt API — не «GPT в браузере», а бесплатный tier для лёгких задач. Имеет смысл выкатить одну фичу с fallback, замерить долю пользователей на on-device пути и только потом планировать экономику API.